Using C4 Diagrams to Model Reliability
To some, the phrase "software architecture" is fraught with visions of overengineered systems designed by former coders who have lost all grip on the day-to-day realities of writing software. And because our industry isn’t always very good at distinguishing babies and bath water, to some the phrase is even synonymous with the dreaded "big design up front" approach to missing deadlines project management. While you can certainly engage with software architecture that way, I find it unfair to dismiss the whole discipline based on some bad practices. After all, the basic assumption of software architecture is that it's good to think about software before writing it, and I find that tough to argue with. That's why I love lightweight approaches to thinking about and documenting software architecture. Architecture Decision Records, streamlined RFC processes, and architectural fitness functions all provide a nice middle ground between Leroy Jenkins-ing our way through a project and having to attend three hour meetings where we stare at UML diagrams with words like AbstractFactoryFactoryAdapterImpl.
One of my favorite such tools is Simon Brown’s C4 Model. The C4 Model is a diagramming method meant to make it easy to look at software from different levels of abstraction. C4 diagrams create a kind of zoomable "map" of your code, with each "zoom level" offering a more detailed view than the one before it. There are four “zoom levels” in a C4 model: context, container, component, and code. While I could describe the levels in detail, the C4 model website already does a great job of that, so go ahead and read that and come back. C4 models have many uses, but one of my favorites is analyzing the reliability characteristics of a design. Let’s look at how we can use C4 diagrams to examine the reliability of our design.
Context
In order to make the discussion slightly less abstract, let's model an example service. Let's pretend that I have a few popular social media accounts, and I want to design a system to fan out a single "post" to all of my social media services. Here's what a context diagram might look like for that.
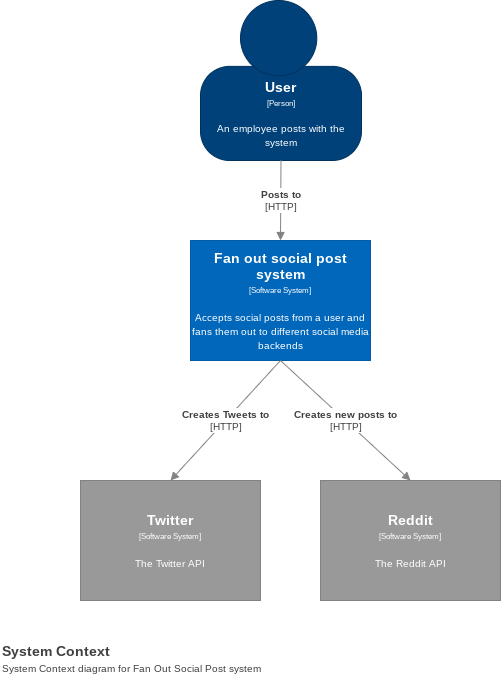
Note: I normally use pencil and paper to make these diagrams. Their simplicity and the fact that I can just use boxes and arrows is one of my favorite things about them. However, I didn't feel like subjecting people to my handwriting, so I used draw.io and a C4 shape library for the examples.
The system context diagram is the highest level of abstraction in a C4 model, and one of the most useful in analyzing reliability. A context diagram visualizes how an application interacts with its users and its external dependencies. This makes it a perfect diagram for thinking about Service Level Objectives and how to deal with failures in systems that you don't control.
Service Level Objectives (SLOs) are one of the fundamental tools in Site Reliability Engineering. They allow us to guage whether or not our system is doing what it's supposed to in the eyes of our users (i.e. the only eyes that matter). Since the system context diagram models our application as a "black box," it's a great tool for thinking through SLOs without getting too deep into the details of our service's implementation. For example, a user of our Fan Out Social System might care more about the UI "feeling snappy" and delivering a feedback message than they do about how long it takes to actually fan out the posts. This would lead to a very different set of SLOs—and likely a different service architecture—than if they cared about how quickly the posts were fanned out.
On the non-user-facing side, we can use the context diagram to think about what happens when—and I should emphasize: it's when, not if—our external dependencies go down. If Twitter is down and our user wants to share their latest sourdough starter picture in all of their social channels, what do we do? Do we drop the request and apologize profusely? Do we set up some sort of temporary storage and retry when Twitter comes back up? There's a spectrum of answers to that scenario between failing silently and retrying until the heat death of the universe, and every step in the retry direction adds complexity and operations overhead to our design. Considering them up front will save us a lot of time later when we're not furiously scrambling because it turns out that Twitter being down somehow deletes our database.
Container
In C4 parlance, a container describes one or more deployable units that interact to make up your service. A C4 container is unrelated to Docker containers, though depending on your architecture they may end up corresponding 1:1.

At this level of abstraction we can make more fine grained decisions about how resilient our service is. You only have so many options for dealing with the reliability of an external dependency, but since you own your containers, you're free to make radical changes if needed to keep them up and running. If your Backend container is failing to keep up with requests, you're free to profile it, tune its performance, or even swap it out with a new implementation.
Container diagrams are also useful for thinking through the user experience of system failure. For instance, if communication between the Single Page App and the Backend containers fails, what do we show our user? Do we fail silently? Every time we fail silently, we're not being the people that Don Norman knows that we can be. Do we show a default 500 page? Product and Design probably won't like that. Do we include a game of Tetris that the user can play while they're waiting on a retry so they don't close their browser and lose the post state? That's complicated to implement, and some people don't like Tetris. There are a lot of ways to deal with failure, but asking the question up front will save you a lot of frustrated users.
Thinking about resilience at this level of abstraction can also help inform our "deployment view" of a container: how many web servers do we need? Do we need read replicas for our database? Is this container a candidate for auto-scaling techniques? What sort of metric should we use for that? Mapping a static container view onto the deployment view can raise many useful questions that can help you understand where monitoring is needed and what the running infrastructure might look like.
Component
The final view that’s useful to us in a reliability context is the component view. A component is a set of language-specific blocks of code; in Java it might be a package, in Python it might be a module, etc. As you might expect, the component view describes how these langauge-specific packages interact in a container.

The component diagram is useful in thinking through specific failure cases at a close-to-code level. For instance, if the Twitter Post Component fails to communicate with the Twitter API, how does it handle that? Does it return an error? Does it have internal retry logic? Does it panic?
Component diagrams are also useful for thinking through the maintainability and changeability of the software, which has a huge effect on how easily you can improve its reliability should you need to. In our example, it's currently easy to add a new social channel type: just create a new implementation of the Post component. But the design also assumes that all social channels can be easily described with the same Post interface. This is probably reasonably true for text-based social platforms such as Twitter, Reddit, or Facebook, but adding a video-based social channel such as TikTok would be difficult in this model.
You might notice that code diagrams are missing from this post. Personally, I don't find code diagrams to be as useful as the other three types, and so I tend to skip them when making a C4 model. However, you should feel free to make one if you feel like it'll help you think about system reliability.
The great thing about lightweight architecture tools like C4 models are that they can be used for many different purposes, and are often easy to apply to existing systems. The next time you have a few minutes and want to think about the reliability of your system, try creating a C4 model for it. You might be surprised at what you learn.